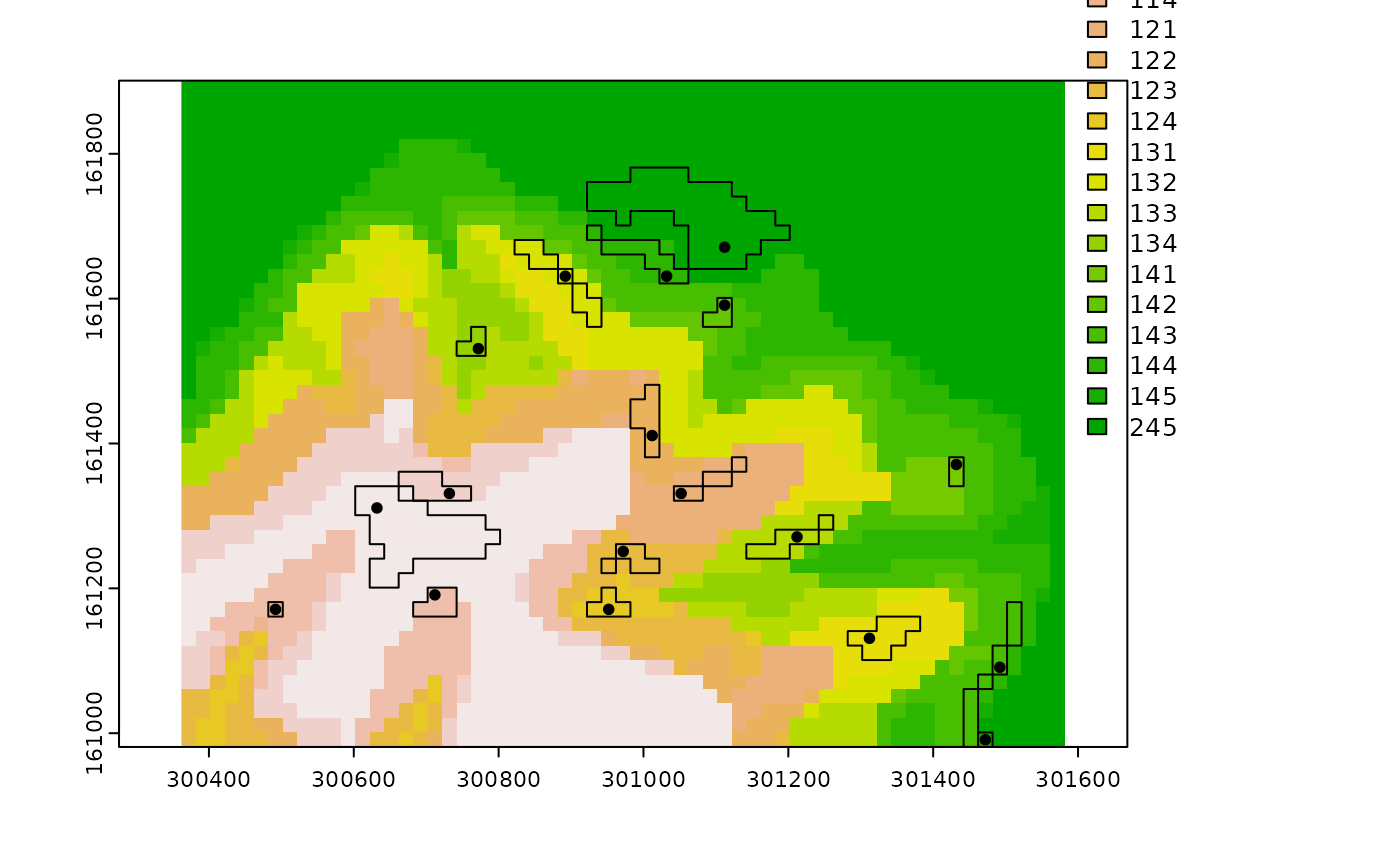
Select Representative Sampling Locations for Stratification Units
Source:R/locations.r
locations.RdSelection of the representative sampling locations based on landscape similarity values. For a give stratification unit, the representative sampling location is the XY position where the highest landscape similarity value occurs. This location is assumed to best reflect the influence that the landscape configuration of a given stratification unit exerts on response phenomena. Currently, two selection methods are supported: (1) maximum similarity within buffer zones ("buffer"), and (2) absolute maximum similarity ("absolute"). For the buffer method, the n largest zones enclosing landscape similarity values above a certain threshold are first identified. Then, for each zone, one sample is placed at the XY location where the landscape similarity value is maximized. For the absolute method, a sample is placed at the XY locations with the n maximum landscape similarity values. In both methods, it is possible to constrain the sampling process to the boundaries of the stratification unit. Constraining the process ensures that the sampling locations determined for a given unit are placed within the boundaries of that unit. See Details for some guidance in the use of this function for classification units.
Usage
locations(
ls.rast,
su.rast,
method = "buffer",
constrained = TRUE,
buf.quant = 0.9,
buf.n = 1,
abs.n = 1,
tol = 1,
parallel = FALSE,
to.disk = FALSE,
outdir = ".",
verbose = FALSE,
...
)Arguments
- ls.rast
SpatRaster, as in
rast. Multi-layer SpatRaster representing landscape similarities to stratification units.- su.rast
SpatRaster. Single-layer SpatRaster representing the stratification units occurring across geographic space. Integer values are expected as cell values (i.e., numeric codes) of stratification units.
- method
Character. String denoting the sampling method. Current options are "buffer" for the maximum similarity within buffer zones method, and "absolute" for the absolute maximum similarity method. Default: "buffer"
- constrained
Boolean. Should the sampling process be constrained to the boundaries of each stratification unit? See Details. Default: TRUE
- buf.quant
Numeric. Number expressed in quantile notation (0-1) indicating the similarity threshold for the creation of buffer zones. Only zones enclosing raster cells with landscape similarity >= buf.quant will be created and thus, considered for sampling. See Details. Default: 0.9
- buf.n
Integer. Positive integer indicating the n largest buffer zones for which sampling locations will be selected (n buffer zones per stratification unit, one sampling location per buffer zone). Default: 1
- abs.n
Integer. When method = "absolute", Positive integer indicating the number of sampling locations to select for each stratification unit. See Details. Default: 1
- tol
Numeric. When method = "absolute", this number will be subtracted from the sampled maximum value of a landscape similarity layer to ensure that the requested number of sampling locations will be found (see Details). The default assumes that landscape similarity values are on a scale of 1 to 100. If these values are on a different scale (e.g., decimal), then, tol needs to be adjusted accordingly. Default: 1
- parallel
Boolean. Perform parallel processing? A parallel backend must be registered beforehand with
registerDoParallel. Keep in mind that the amount of RAM to allocate when performing parallel processing can result prohibitive for large data sets. Default: FALSE- to.disk
Boolean. Should output SpatVector(s) (as in
vect) be written to disk? Default: FALSE- outdir
Character. If to.disk = TRUE, string specifying the path for the output SpatVector(s). Default: "."
- verbose
Boolean. Show warning messages in the console? Default: FALSE
- ...
Additional arguments, as for
writeVector.
Value
If method = "buffer" and constrained = TRUE, a list with the following components:
locations: SpatVector of point geometry. Each point in this vector represents the sampling location placed at the maximum landscape similarity value within a stratification unit's buffer zone. Tabular attributes in this SpatVector are (1) SU = stratification unit's numeric code, (2) land_sim = landscape similarity value, (3) x = X coordinate, and (4) y = Y coordinate.
buffer: SpatVector of polygon geometry. Each polygon in this vector represents the buffer zone of an stratification unit.
If method = "buffer" and constrained = FALSE:
locations: Same as locations from method = "buffer"
and constrained = TRUE.
If method = "absolute":
locations: SpatVector of point geometry. Each point in this vector represents the sampling location placed at the maximum landscape similarity value for an stratification unit. Tabular attributes in this SpatVector are (1) SU = stratification unit's numeric code, (2) land_sim = landscape similarity value, (3) x = X coordinate, and (4) y = Y coordinate.
Details
Except when buf.n = 1 or abs.n = 1, the number of returned sampling locations per stratification unit may be smaller than requested, especially when constrained = TRUE. For the constrained buffer method, reducing the landscape similarity threshold value buf.quant will not always result in more buffer zones; i.e., more sampling locations. The reason for this is that reducing the threshold value for the creation of buffer zones may actually promote the spatial contiguity of zones. For instance, two buffer zones created at buf.quant = 0.9, may be merged into a single buffer zone when buf.quant = 0.80. This will occur if the raster cells between the two buffer zones satisfy: landscape similarity >= quantile(landscape similarity, 0.8). For the absolute method, increasing the value of the tol argument will ensure a safer search for n sampling locations and thus, greater chances of getting the total number of requested sampling locations per stratification unit.
Note that this sampling scheme can be applied for classification units. In order to do this, one should replace the multi-layer SpatRaster of landscape similarities with a multi-layer SpatRaster of spatial signatures. One should also replace the raster layer of stratification units with that of classification units.
See also
Other Functions for Stratified Sampling:
observation()
Examples
require(terra)
p <- system.file("exdat", package = "rassta")
# Multi-layer SpatRaster of landscape similarities
fls <- list.files(path = p, pattern = "su_", full.names = TRUE)
ls <- terra::rast(fls)
# Single-layer SpatRaster of stratification units
fsu <- list.files(path = p, pattern = "strata.tif", full.names = TRUE)
su <- terra::rast(fsu)
# Get 1 representative sampling location per stratification unit
rl <- locations(ls.rast = ls, su.rast = su)
# Plot representative locations (including buffer areas)
if(interactive()){
plot(su, type = "classes", fun = function() c(points(rl$locations),
polys(rl$buffers))
)}